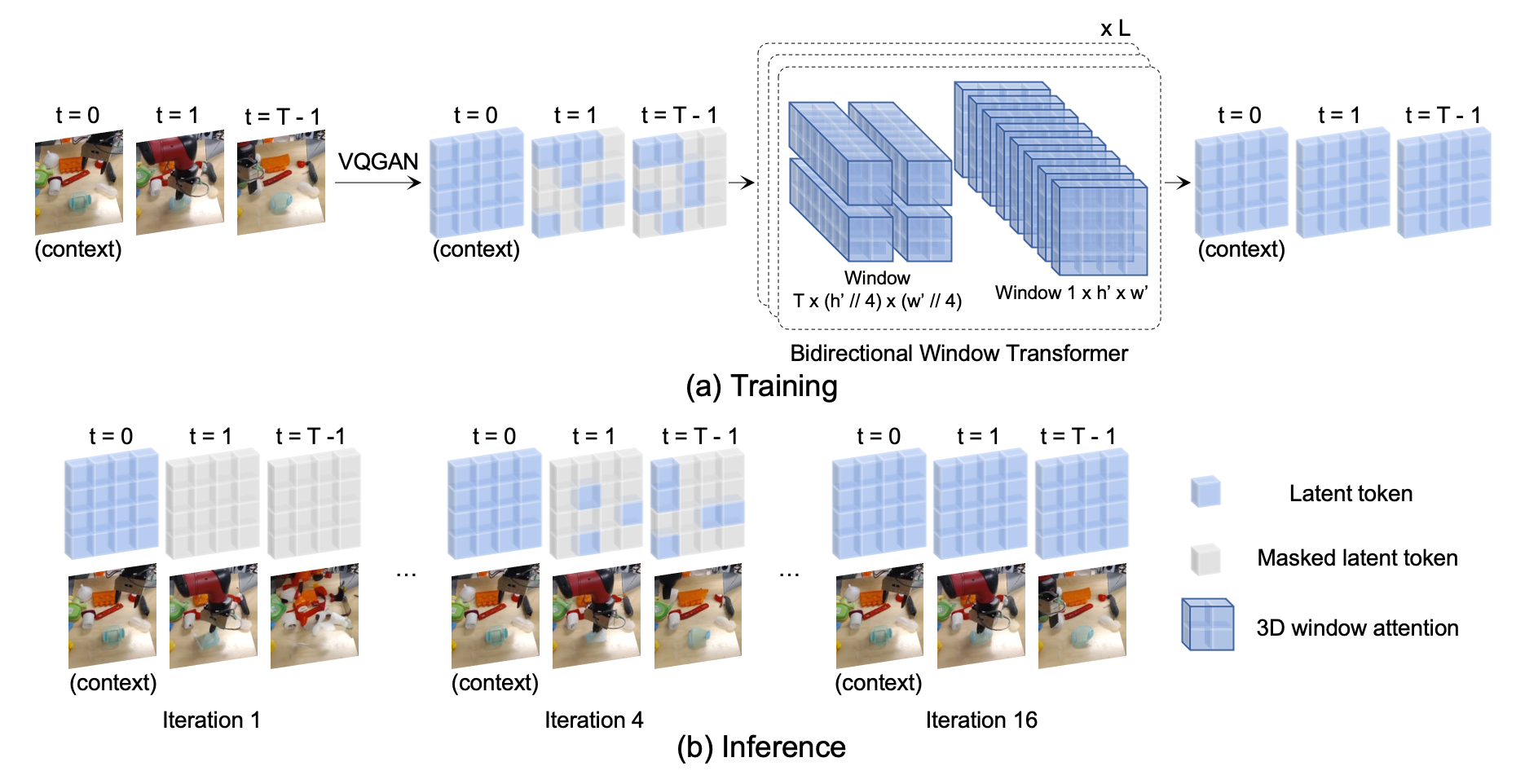
Abstract
The ability to predict future visual observations conditioned on past observations and motor commands can enable embodied agents to plan solutions to a variety of tasks in complex environments. This work shows that we can create good video prediction models by pre-training transformers via masked visual modeling. Our approach, named MaskViT, is based on two simple design decisions. First, for memory and training efficiency, we use two types of window attention: spatial and spatiotemporal. Second, during training, we mask a variable percentage of tokens instead of a fixed mask ratio. For inference, MaskViT generates all tokens via iterative refinement where we incrementally decrease the masking ratio following a mask scheduling function. On several datasets we demonstrate that MaskViT outperforms prior works in video prediction, is parameter efficient, and can generate high-resolution videos (\(256\times256\)). Further, we demonstrate the benefits of inference speedup (up to \(512\times\)) due to iterative decoding by using MaskViT for planning on a real robot. Our work suggests that we can endow embodied agents with powerful predictive models by leveraging the general framework of masked visual modeling with minimal domain knowledge.
Qualitative results
Here we present additional qualitative videos of results from MaskViT. Ground truth videos are on the left of each pair while predicted videos are on the right. A red border indicates that the frame is a (VQ-GAN reconstructed) context frame, and a green border indicates a predicted frame.
BAIR (64x64, action-free)
KITTI (256x256)
RoboNet (256x256)
Real robot experiments
We demonstrate how the performance improvements afforded by MaskViT allow it to be leveraged for control through visual planning. We show examples of predicted plans and overall trajectories executed on a Sawyer robot by planning using MaskViT as an action-conditioned forward dynamics model.



